
I joined VAPAR as their Lead Data Scientist in May, meaning that I’ve just passed my first six months as a ‘Vaparino’. So far, it’s been a really interesting journey; the water industry brings some unique challenges that have forced me to learn and solve uncommon problems in my role.
Firstly, some context - VAPAR is an Australia-based start-up which provides end-to-end AI-based solutions for assessments of assets; specifically sewer and stormwater pipes. VAPAR’s platform performs automated inspections of these pipes to find defects, report the exact locations of the defect and provide repair recommendations to our clients.
For asset owners like Councils and Water Utilities, time and money are hugely important, connected considerations. Because of the massive lengths of networks these asset owners are responsible for managing, pipes will sometimes go decades without receiving an inspection. This means that asset owners are at risk of not addressing critical issues on time, increasing the risk of service disruption dramatically. That’s where VAPAR can improve the process; we provide time-efficient, automated assessments that allow asset owners to save on pipe repairs, and also protect against unplanned repairs.
As a Data Scientist, the most crucial lesson to remember for a new use-case is to get acquainted with your data as deeply as possible. Once you’ve got a solid understanding of the data, you’re able to imagine solutions to your problems with far greater ease. Being new to the water industry, there were two key challenges related to machine learning that needed to be overcome.
Duplicate Defect Reporting
When a contractor is recording pipe inspection footage, they will move the camera through the pipe at inconsistent speeds, including instances where the camera is stationary for a couple of seconds. They will also tilt the camera head around to get a better look at the inside of the pipe.
Due to the significant computational cost involved, our platform samples frames rather than analyse every frame from a piece of footage. Because of this, and combined with the inconsistent speed of camera movement and operation, it’s possible for a defect to be observed initially from a distance, before being reported a second time when still in the field of view.
Such duplication of defects can have a huge effect on the data we use to provide advice to our clients. If left unaddressed, this could lead to inaccurate, misleading repair recommendations which could result in clients assigning budget for repairs to pipes which didn’t require them, creating huge inefficiencies.
Start and end node detection
Start and end nodes in the context of pipe infrastructure refers to the beginning and end of each piece of pipe infrastructure (where a maintenance cover will be located). For stormwater pipes, these might be the grates where stormwater runs off from the street and into the pipes.
Because start and end nodes are the points at which cameras are both inserted and retracted from, there will often be footage captured of them in the pipe inspection footage which can cause defects to be identified which aren’t relevant to the pipe condition assessment. A common example is when the inspection camera points directly upwards at the vertical well leading to the surface, or pans around to capture the other pipe connections to the node.
If we were to leave reported defects from start and end nodes in our data without adjustment, we would be reporting large volumes of irrelevant defects in our pipe condition assessments for our clients.
How we approached these problems
In order to develop models which could account for these problems, we developed a process which would allow our machine learning models to identify instances where they occurred, and take appropriate action to prevent these problems from impacting the results and recommendations which we provided to our clients.
When a client uploads footage to our platform, it provides initial defect detection as an output. If this data were to be provided to the client immediately, we simply wouldn’t be providing accurate advice or recommendations.
Instead, the VAPAR team took the data that was initially output by our platform, and performed some further automated analysis and data preparation steps on it, taking in additional factors about the footage.
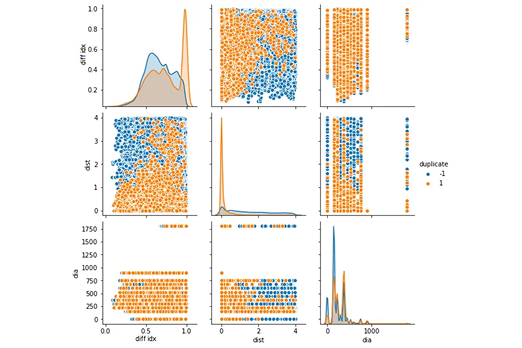
Once preparation was finalised, we fed this pre-processed data into a machine learning model, where, combined with the distance information from the dataset, we were able to define a model which could automatically identify duplicate frames.
Using this same methodology, we were also able to define a model which would exclude defects found in start and end nodes from the analysis and recommendations provided to our clients.
Without a deep understanding of the data and the challenges it poses, these solutions would have been very challenging to identify, test and implement. Domain knowledge of your use case is key to developing robust, dynamic solutions to provide the best possible outcomes.
=================
Interested in learning about the computer vision and deep learning problems in CCTV pipe inspections (and how we’ve overcome them)? Stay tuned for future blogs!
=================
Saeed Amirgholipour PhD. is an AI Architect, Full Stack Data Scientist, and Data Science/ AI Lead Trainer with over 10 years of industry experience, including CSIRO’s Data61, Australia’s leading data innovation group. His experience spans across end-to-end large-scale innovative AI, Data Science, and analytics solutions. Saeed has a passion for solving complex business problems utilizing Machine Learning (ML) and Deep Learning (DL) models.
Articles


